Some of you may have already heard about the computer cache in your curriculum or some of you may have not. But this article is intended for all of those who want to understand cache concepts. The next part of it consists of developing a cache simulator using C programming language. I believe that this article will give a clear insight of cache and how it works. So lets see what we will be learning in this series of articles.
Cache Introduction
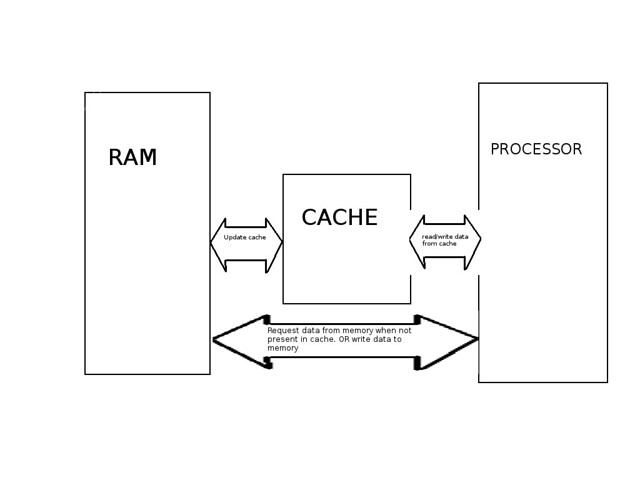
The first thing we should know what are we talking about. Cache is a highly efficient (really fast) memory which can bring data to processor at a much more speed than our typical RAM. CPU cache memory operates between 10 to 100 times faster than RAM, requiring only a few nanoseconds to respond to the CPU request. Cache operates faster because it resides usually on the same chip as the processor. But it makes them expensive. Also caches are smaller in size (around 512KB to 3MB) whereas computer RAM can be upto 16GB. The reason why caches are smaller is because it makes the mapping techniques faster and also reduces cost for a normal computer. So cache behaves a temporary storage for RAM data. Computer processor looks for data in cache first and if it is not present, then it gets the data from RAM and stores it in cache for future reference.
Cache Organisation
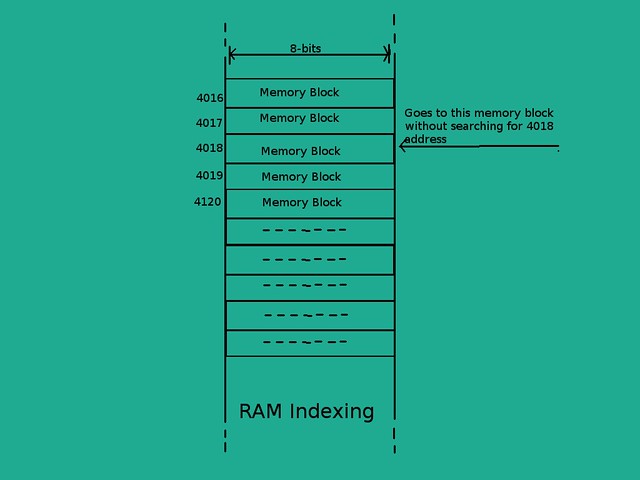
As we know now that cache is smaller than RAM, it cannot store all the RAM data. In RAM memory, a memory cell number serves the purpose of index for the memory which is also our physical address. For example, if we want to store x on some address 32 then this means that we just go to 32nd cell number into RAM and writes our data. So we don't need to consider an index table for RAM because RAM is all the memory we have got.
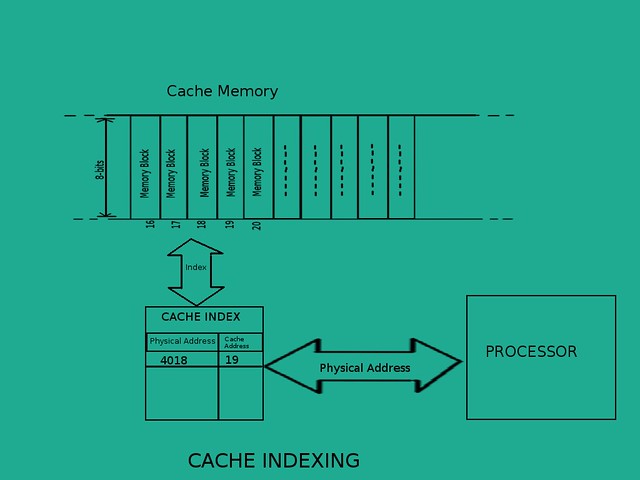
But the same address cannot work for cache memory because lets say our cache has only 16 cells. This means we need to create a seperate index table for our cache memory into which we will search for cache cell number which contains data for given physical address. For our earlier example, if our cache has only 16 memory cells and we want to search for data for address 32 then we will look into cache index and find which cache cell holds data for address 32. One way would be to have a 16-entry index table where each entry represents the cache cell number and contains the physical address for which the data is stored in that particular cell. The following picture will give you a better idea than my words (But read my words again after looking at the picture, you will understand what i am saying).
So this is how it works.There are several ways to find a physical address in cache index. One of which would be to search all index entries one by one but that will make our cache inefficient. Thats why we use mapping techniques which maps RAM addresses to Cache addresses and make it efficient. The next article will make you understand what are the main mapping techniques are and how they work.
Understanding a few Concepts
There are 3 mapping techniques all of which have their advantages and disadvantages. But all of them have some things in common. Each technique breaks a physical address into some components which we will discuss first. If you don't understand what these terms mean then its not a problem as the picture will make their meanings more clear. There are also some formulas related but you don't need to cram them. You will understand how these formulas are derived on your own.
- Word: This is the unit of data which is transferred for each operation.
- Word Length: This is the maximum number of bytes allowed to transfer in one operation. For eg., In a 32-bit CPU, word length is 4 bytes (32 bits/8 bits)
- Block: A group of words which is transferred between cache and main memory is called a block. This implies that whenever the requested data is missing from cache then a whole block of words is transferred from main memory to cache instead of just one word. The significance of transferring a whole block comes from the fact that most of the times data is stored sequentially by a program (stack memory) and thus transferring a whole block reduces the chances of next failed request. So all data transfer between cache and main memory happens in forms of blocks but data transfer between any memory and CPU happens in word.
- Cache Hit: When the processor requests data from cache and finds it in the cache, then it is said to be a cache hit.
- Cache Miss: Just the opposite of cache hit. When requested data is not in cache then it is a cache miss. Caches are designed to reduce cache misses and to increase cache hits. In case of a cache miss during data read, the required data is read from main memory after transfering a block of data to cache.
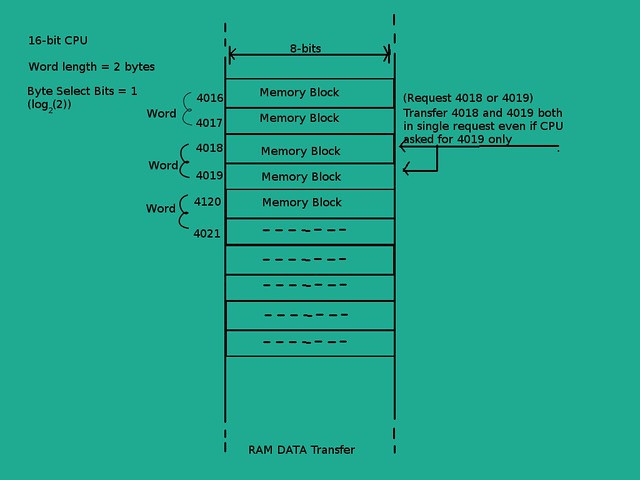
- Byte Select Bits: These are the lower significance bits of an address which are used to select a specific byte of a word to select for operation. This is internal for a CPU. That is when a CPU asks for some data, whole word is transferred and which byte of that word is used for operation is out of our concern. For eg., In a 16-bit CPU, total 2 bytes (word length) are transferred for each request. This means only 1 bit (
log(word_length)) is used for byte select. If the address is of 16 bits (64KB RAM) then we look at only more significant 15 bits (address bits - byte select bits) to look for data in RAM and transfer the 2 bytes regardless of what the last bit was. So if CPU asks for address XXX0010 or XXX0011 (XXX - first 12 bits) then we look for same location that is XXX001 (last bit ignored) and send both bytes in each case i.e. XXX0010 , XXX0011 - Cache Line bits: Consider the cache index is index of some book and it contains several pages. So our index is written on several pages. Lines bits determine the page number on which to search for our physical address. This way we save our time by limiting our search to only one page instead of many. Remember that more entries on one page means that we will have to match each entry against given address. This means a linear search for the address is necessary after finding the page number of our memory address. Number of line bits depend on mapping techniques which we will cover in next article. Line bits are next bits after byte select bits which help us to limit our search for address in cache index
- Tag Bits: After finding the page number, we will have to search our address. But we do not need to store the whole address as index entries because we already know some part of it which are the line bits and word bits. So we store the remaining bits of the address (excluding byte select, word and line bits) which are called the tag bits. Hence an address is broken into 4 parts : tag bits, line bits, word bits, byte select bits.
- Word Bits: As the data transfer between main memory and cache memory happens in blocks, some bits are needed to transfer the required word from cache to processor. These are the word bits. Cache index tells the address of memory block in cache memory. The correct word which needs to be transferred is decided by word bits.
- Valid Bit: This bit is used to indicate whether the data stored in the cache is valid or not (1- valid, 0-invalid). We need this bit in our index so we can keep track of memory locations which contain valid data. If we need to clear the cache, we can just set valid bit of each entry to 0
- Dirty Bit: This bit is important in write back policy. When some data is loaded into cache and it is updated then it is marked as dirty. So that when the CPU needs to replace (which happens frequently) the data , it can save the updated data into RAM before replacing it.
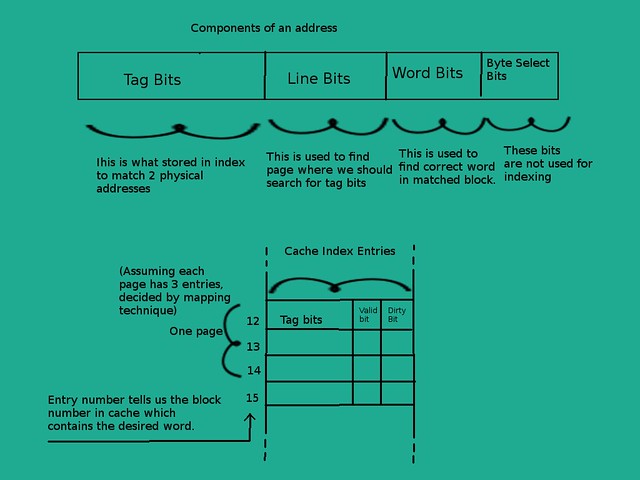
Now lets see how the whole process of reading data from cache takes place
- Cache index contains several pages depending on the mapping technique
- Each entry of index contains tag bits, valid bit and dirty bit
- Entry number represents the location of block in cache memory.
- Processor sends a physical address to cache of which the data is required.
- Physical address is broken into components in the following manner (Starting from lower bits)
- Byte Select Bits = log(word_length)
- Word Bits = log(number_of_words_per_block)
- Line Bits = log(number_of_pages)
- Tag Bits = remaining_bits_of_address
- Correct Index Page is found using line bits
- Each entry of the page is matched with tag bits
- Correct word is found by adding word bits to matched entry.
- Found word is transferred to processor if it is valid (valid=1)
This was pretty much about the terms we need to understand before moving on. Make sure you understand these concepts because in the next article, these terms will be repeating a lot.
Comments
Post a Comment
Comment on articles for more info.