
In the last post, we saw how collision in handled in a hash table. Now its time to explore some real world scenarios because come on, what is the use of learning all this if we can't apply it in real world softwares. As we learned that open addressing and chaining were both good in different scenarios only if we met a condition that the keys are uniformaly distributed. But its not the application job to pass distributed keys to hash tables, its our job to map any key to some random location. We do this using a hash function (or prehash function, whatever term you prefer). A hash function should map the keys as uniform as possible. So lets discuss some decent hash functions to some high end hash functions.
Desining Hash Functions
Hash Functions do the job of mapping a key to some location in hash table.
This is achieved by doing some fixed operations on the key and generating a number
between 0 to the capacity of table. Hash functions highly determine the overall
complexity of hash table for insert and search operations because as we saw in
open addressing if a lot of keys are mapped to same location then it will shorty
form a clusture there and then inserting a new key or searching an old key will
not be a O(1) operation anymore. So we want our hash function to
have some properties. Lets see what they are.
Properties of Hash Functions
Desirable properties of a hash function are:
- Uniform Distribution: Each key should be equally likely hashed to any slot of the table independent of where other keys hash. This means that hashing of a key should not be related to hash table size or placement of other keys.
- Time Independent: Hash values of keys should be changed over time. This implies to the fact that if i hash my key now and if i hash the same key one year later, the resulting hash values in both the cases should be same.
Basic Hash Functions
As we saw what we want in our hash functions, we are ready to write some. We are making one assumption that the key is always integer. Later we'll see how to convert any object to an integer atleast in c/c++. Some of the hash functions which are used commonly are described below.
- Division Method: In this method, we take modulo of key with table size.
This will generate a number between 0 and size of table. This may create a problem
if keys and size of table have common factors, then only some of table space will
be utilized.

-
Multiplication Method: Opposite of the division method is multiplication method.
In this method we multiply the key with some FIXED number and take out a bunch of bits.

-
Universal Hashing: In this method, we compute a value by multiplying the key with
prime number and then taking the mod with size of table. The worst case possibility of colliding
two keys is
1/(size of table)which is ideal situation.



Cryptographic Hash Functions
Hash Functions are not only used to compute the location of a key in a table but also to convert any given key or should we say any data to a fixed length digest. This digest is unique for each key and thus it is made sure that no 2 keys have same digest. Such type of hash functions are used in cryptography to encrypt a message or a password to transfer it safely from one place to another. Cryptographic hash functions must have a property other than the above two and that is they should be one way. This means that it must not be possible to recover the key from its digest. There are many widely used hash functions which are either used for encryption or just to compute checksum. Two most commonly used and famous hash functions are MD and SHA. We won't go in detail how these work because there are libraries to use these hash functions. Lets see what are those.
-
MD (Message Digest): The MD family comprises of hash functions MD2, MD4, MD5
and MD6. It was adopted as Internet Standard RFC 1321. It is a 128-bit hash function.
MD5 was the most popular hash function for some years until in 2004, collisions were
found in MD5. Since then it is not recommended to use but still people use it for
less sophisticated applications where collisions are allowed.

-
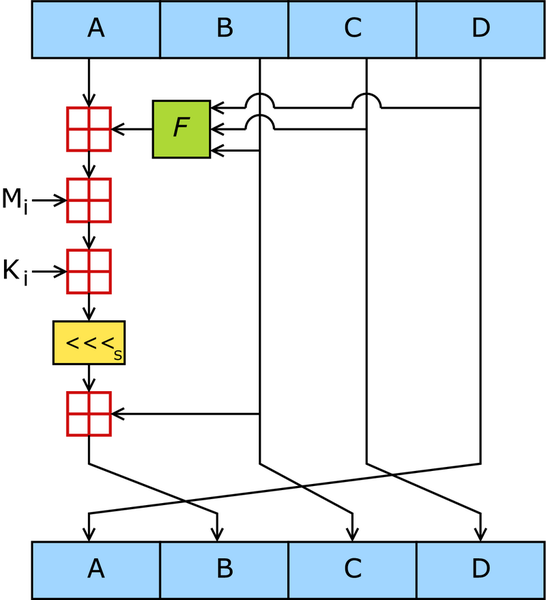
SHA (Secure Hash Function): Family of SHA comprise of four SHA algorithms;
SHA-0, SHA-1, SHA-2, and SHA-3. SHA-1 is most widely used hash function of this
family. It is also employed in SSL (Secure Socket Layer).


This was it for this post. We'll see in the final post of this series how python manages it dictionaries and lists. Also share this article to your nerd friends to make them aware of where the world is heading. Keep Hashing
Comments
Post a Comment
Comment on articles for more info.